Factorial designs: power from means and SD
0.2.0
Here we compare the results of PAMLj with other software that performs power analysis. In particular, we will compare our results with R pwr package, Superpower R package, and G*Power.
Data
Factorial designs power analysis from
Expected Means of PAMLj
requires a dataset with the expected means and the standard deviations
for the desin cells one is planning. Factors of the design should be
listed as categorical factors, and their means and sd should be listed
in subsequent columns. For instance, a simple design with two groups,
can be prepared like this:
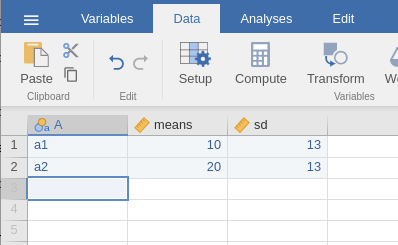
When data are defined, one can use the Factorial designs power analysis from Expected Means interface in define the design factors, their means and standard deviations.
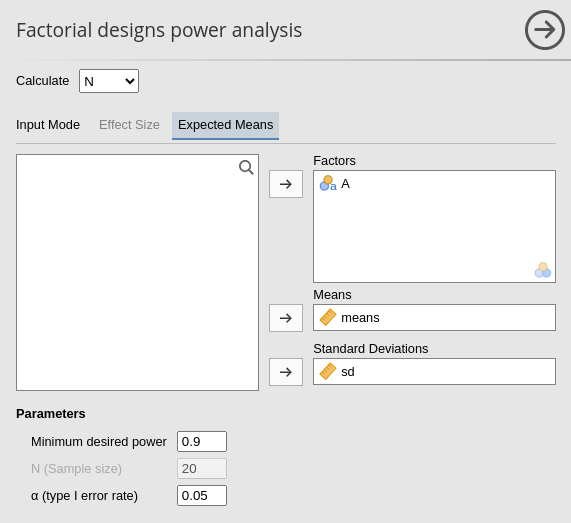
As soon as the variables are defined, the effect sizes are computed together with the power parameters.
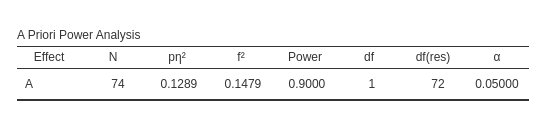
As a quick test, we can use G*Power to check the
results, using its interface for inputing the means and the standard
deviations.
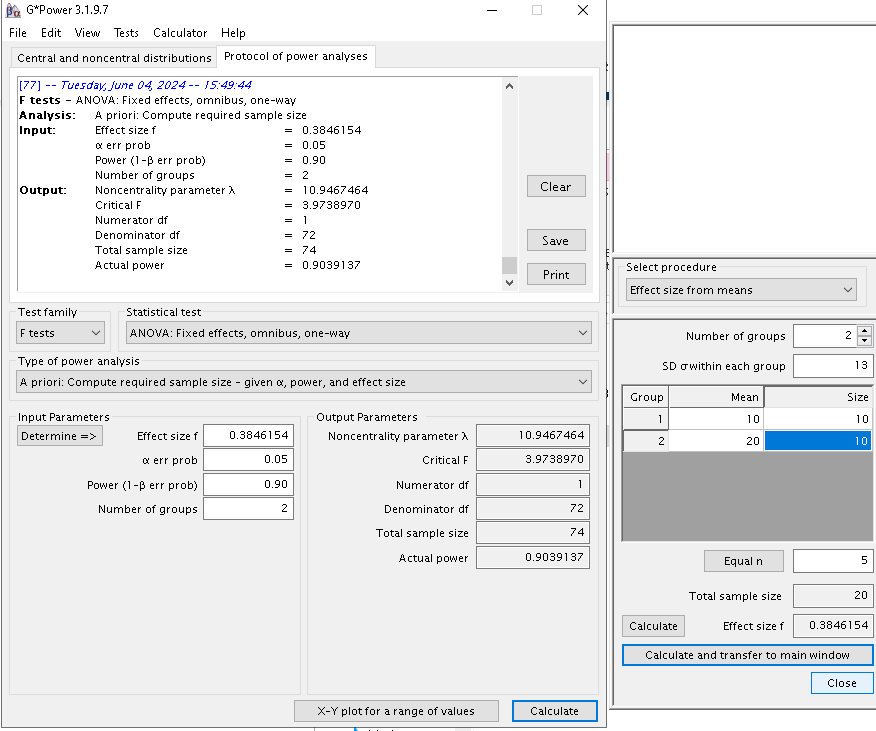
Results are the same.
Unfortunately, G*Power does not allow to input means and sd other than for one-way between-subjects designs, so we cannot test PAMLj for more complex designs. For this purpose, we can use Superpower R package, which allows computing the expected power starting from an array of means and standard deviations.
Between-subjects ANOVA
We can use the dataset factorial which comes with PAMLj in the jamovi
data library.
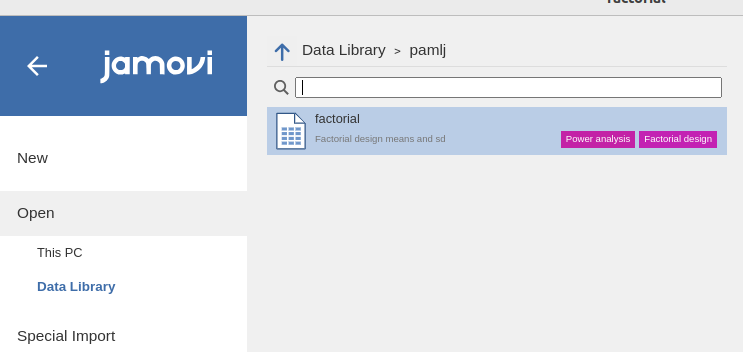
Data describe the means and standard deviations for a 2X3X2 design.
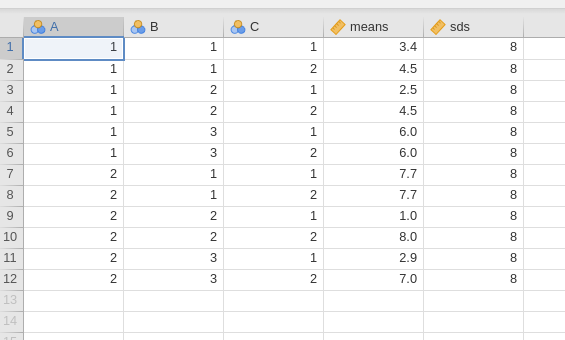
In Factorial designs power analysis from
Expected Means we can simply input the factors, indicating
also the column representing the means and the one representing the
standard devations.
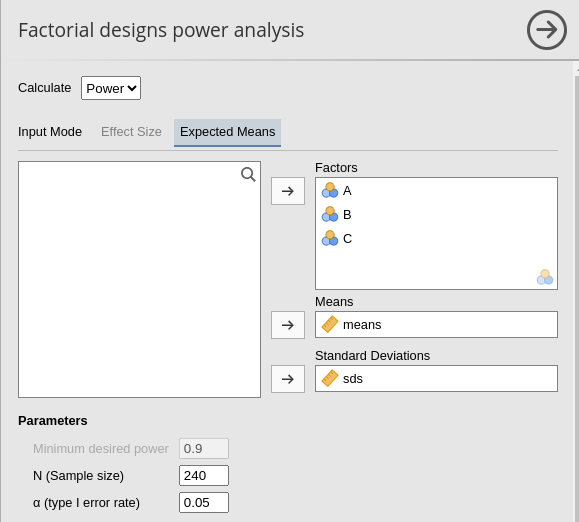
For the purpose of computing the expected power, we can set the sample size to 240, corresponding to 20 cases per cell.
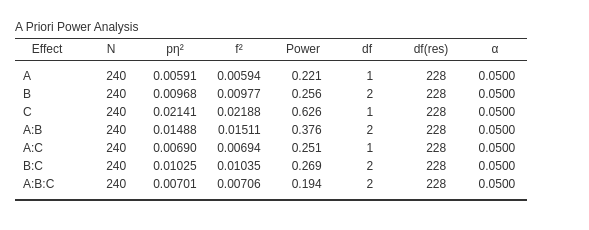
PAMLj computes the expected effect sizes and the expected power for all factors effects and their interaction.
For comparison, we can use Superpower employing the
following code:
ds<-pamlj::factorial
std<-8
n<-20
des_str<-"2b*3b*2b"
design <- Superpower::ANOVA_design(design = des_str,
#sample size per group
n = n,
#pattern of means
mu =ds$means,
sd = std,
plot=FALSE
)
exact_result <- Superpower::ANOVA_exact(design,
alpha_level = .05,
verbose = FALSE)
zapsmall(exact_result$main_results)## power partial_eta_squared cohen_f non_centrality
## a 22.12255 0.00622 0.07909 1.42604
## b 25.56930 0.01018 0.10142 2.34531
## c 62.62434 0.02251 0.15176 5.25104
## a:b 37.63354 0.01565 0.12610 3.62552
## a:c 25.06133 0.00726 0.08550 1.66667
## b:c 26.89367 0.01078 0.10440 2.48490
## a:b:c 19.44604 0.00738 0.08620 1.69427It is easy to check that the expected power is almost identical
(apart for rounding) for all effects. It is worth noticing that despite
the expected power is identical for the two software, they produce
different effect size indices. This is due to the way the two software
compute the effect sizes. Superpower builds a dataset of
the input sample size and estimate the effect sizes, whereas PAMLj computes the estimated effect sizes in
the population. Because these effect size indices are upward biased, in
small to moderate sample sizes they tend to be larger than in the
population. Indeed, if we ask Superpower to compute the
effect sizes for a very large sample, the estimated indices converge to
the ones obtained in PAMLj.
ds<-pamlj::factorial
std<-8
n<-5000
des_str<-"2b*3b*2b"
design <- Superpower::ANOVA_design(design = des_str,
#sample size per group
n = n,
#pattern of means
mu =ds$means,
sd = std,
plot=FALSE
)
exact_result <- Superpower::ANOVA_exact(design,
alpha_level = .05,
verbose = FALSE)
zapsmall(exact_result$main_results)## power partial_eta_squared cohen_f non_centrality
## a 100 0.0059 0.0771 356.5104
## b 100 0.0097 0.0989 586.3281
## c 100 0.0214 0.1479 1312.7604
## a:b 100 0.0149 0.1229 906.3802
## a:c 100 0.0069 0.0833 416.6667
## b:c 100 0.0102 0.1018 621.2240
## a:b:c 100 0.0070 0.0840 423.5677Repeated measures designs
Let’s now assume that the design we have analyzed before was a repeated measures design. In repeated measures designs, to compute the power parameters from means and standard deviations, one needs to anticipate the average correlations among repeated measures. Let’s assume that the repeated measures correlate, on average, .2. We can setup the analysis as before, but in the Repeated Measures tab, we can declare which factor is within-subjects and input the expected correlation. In this example, we set the sample size to 50.
Having set the factors as repeated measures factors and with a non-zero correlation changes the effect size estimation and the estimated power.
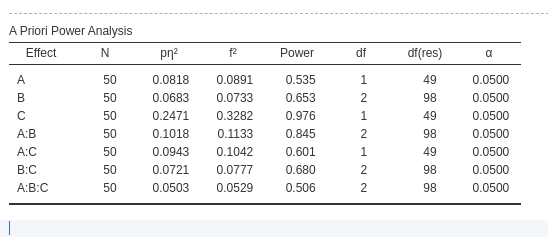
We should also note that the residuals degrees of freedom are now different, because they depend on the sample size and degrees of freedom of the effect.
For comparison, we run the same analysis with
Superpower.
ds<-pamlj::factorial
std<-8
n<-50
des_str<-"2w*3w*2w"
r<-.2
design <- Superpower::ANOVA_design(design = des_str,
#sample size per group
n = n,
#pattern of means
mu =ds$means,
r=r,
sd = std,
plot=FALSE
)
exact_result <- Superpower::ANOVA_exact(design,
alpha_level = .05,
verbose = FALSE)
zapsmall(exact_result$main_results)## power partial_eta_squared cohen_f non_centrality
## a 54.36549 0.08336 0.30157 4.45638
## b 66.25727 0.06958 0.27347 7.32910
## c 97.78008 0.25087 0.57869 16.40951
## a:b 85.21552 0.10363 0.34001 11.32975
## a:c 60.92486 0.09608 0.32603 5.20833
## b:c 68.95522 0.07342 0.28149 7.76530
## a:b:c 51.50017 0.05126 0.23244 5.29460We can see that the results are pretty similar. The difference is due
to the fact that Superpower estimates power based on the
sample estimates of the effect size, whereas PAMLj uses the population effect size. To add
an additional proof, we can ask GPower to compute the power for a
Repeated measure effect with effect size \(p\eta^2=.0818\), 1 DF (two measures), all
within effects (1 group) with \(N=50\)
(and SPSS effect size, cf. Rosetta:
Software inconsistency in RM ANOVA
Rosetta: Factorial power from
effect size).
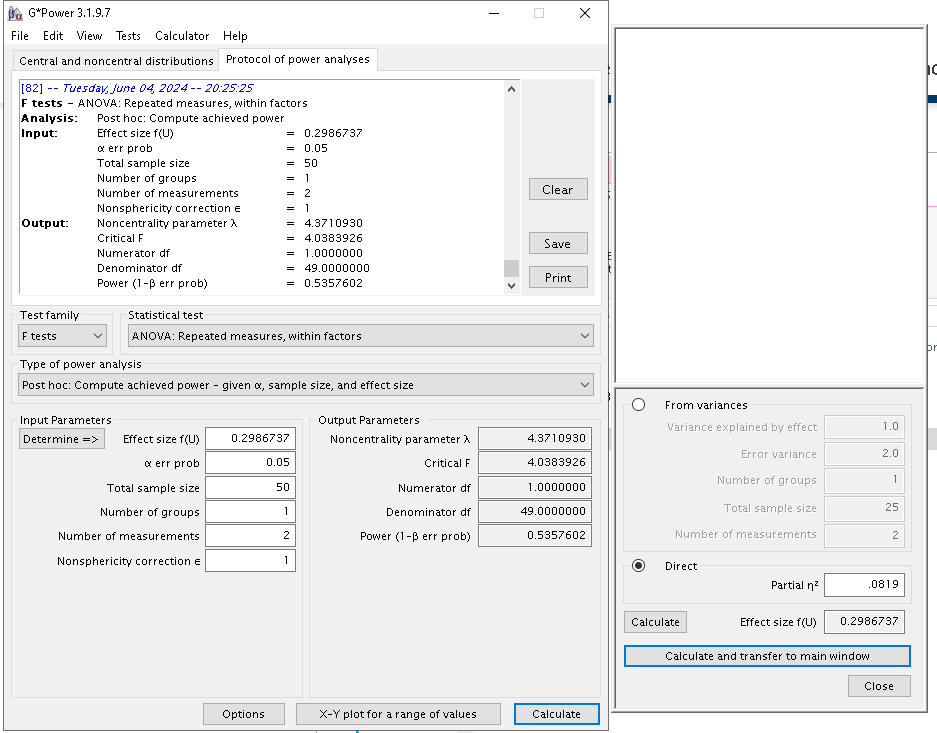
Results are indeed identical to PAMLj results.
Mixed ANOVA
Expected Power
We can now test the module with a mixed design, with one repeated measure factor (say A) and the other two (B and C) as between-subjects factors. This yields a design with 6 groups, so we can set the sample size to 120, corresponding to 20 cases per group. As for the correlations among repeated measures, we can set it to .5. In PAMLj, we simply set up the input as follows.
and for the repeated measures we have
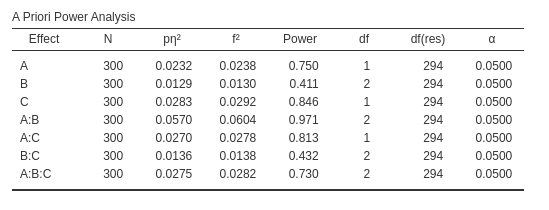
Results are the following:
For comparison, we run the same analysis with
Superpower.
ds<-pamlj::factorial
std<-8
n<-50
des_str<-"2w*3b*2b"
r<-.5
design <- Superpower::ANOVA_design(design = des_str,
#sample size per group
n = n,
#pattern of means
mu =ds$means,
r=r,
sd = std,
plot=FALSE
)
exact_result <- Superpower::ANOVA_exact(design,
alpha_level = .05,
verbose = FALSE)
zapsmall(exact_result$main_results)## power partial_eta_squared cohen_f non_centrality
## b 40.34061 0.01312 0.11531 3.90885
## c 83.85936 0.02891 0.17253 8.75174
## b:c 42.45058 0.01389 0.11869 4.14149
## a 75.85217 0.02368 0.15573 7.13021
## b:a 97.40707 0.05808 0.24831 18.12760
## c:a 82.05198 0.02756 0.16836 8.33333
## b:c:a 73.90719 0.02801 0.16975 8.47135All considering, results are enough similar.
Required N
To validate PAMLj computation of the required sample size, we can use
GPOWER. Using the factorial dataset, assuming one repeated
measure factor (A) with correlation equal to .5, the other two (B and C)
as between-subjects factors, with required power set to .90, we obtain
the following results.
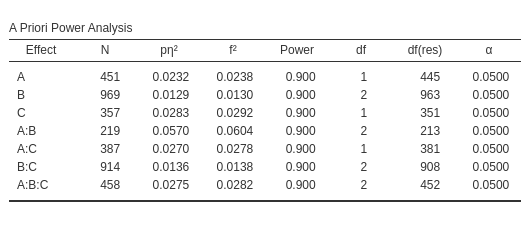
We can now pick the interaction \(A*B\), with \(p\eta^2=.0293\) with 2 degrees of freedom.
In GPower, we can use
ANOVA: Repeated measures, within-between interactions, with
Options set to SPSS. To approximate the
results, we can set the Number of repeated measures to 2,
and the Number of groups to 3 (factor B has three
levels).
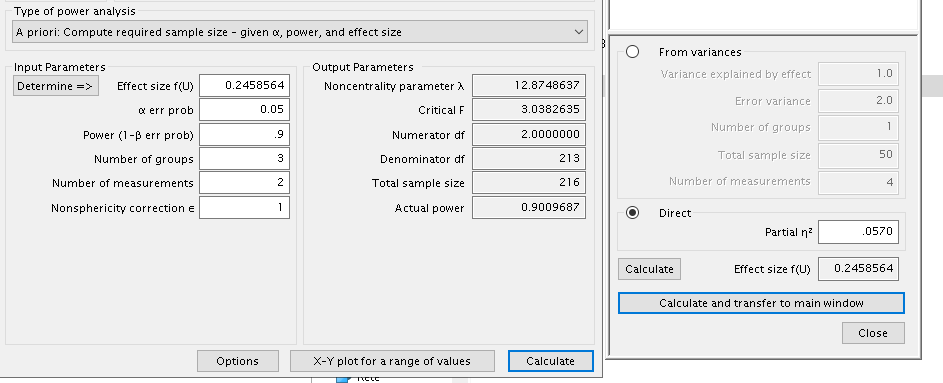
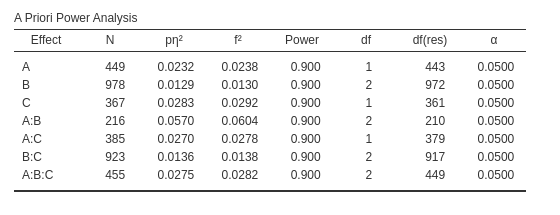
The results are similar but not very close, being the \(N=219\) for PAMLj and \(N=216\) for GPower. However, in this case
it is not a matter of approximation or rounding. Notice that both
software indicates the same effect size and the same degrees of freedom,
PAMLj gives a slightly larger required N because PAMLj takes into the
account that the whole model has three factors, whereas this information
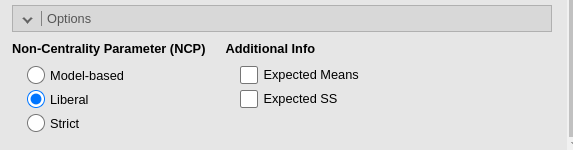
cannot be passed to GPower. In fact, PAMLj yields the same results of
GPower if one selects the option Liberal in the
Non-centrality parameter. The option Liberal,
in fact, estimates the required N without considering the whole model
degrees of freedom, but only the effect degrees of freedom (cf
Extreme values warnings
F-Test Non-centrality parameters).
Comments?
Got comments, issues or spotted a bug? Please open an issue on PAMLj at github or send me an email